Bài báo này trình bày kết quả nghiên cứu ứng dụng kỹ thuật học máy để xử lý dữ liệu đào tạo và dữ liệu tuyển sinh đại học, trường hợp của trường Đại học Thủ đô Hà Nội, từ năm 2016 đến năm 2020. Trên cơ sở kết quả xử lý dữ liệu và sự hỗ trợ từ chương trình ứng dụng kỹ thuật học máy; nhóm tác giả phân tích, đánh giá và dự báo kết quả học tập của sinh viên dựa trên dữ liệu tuyển sinh, dữ liệu học tập năm thứ nhất và năm thứ hai đại học. Từ đó, chúng tôi đề xuất các kiến nghị về chính sách đào tạo, chính sách tuyển sinh, phương pháp giải quyết triệt để và định lượng các vấn đề trong tuyển sinh đại học.
Giới thiệu
Cách mạng công nghiệp 4.0 được định hình không tách rời với dữ liệu và phân tích dữ liệu, đặt ra thách thức với các tổ chức (trong đó có trường đại học) khi phải xử lý tốt dữ liệu để có thể nâng cao năng lực hoạt động, hiệu quả quản lí và giảm thiểu rủi ro thất bại.
Trong thời đại công nghệ dựa trên dữ liệu lớn, việc các trường đại học cần đổi mới mô hình quản trị và nâng cao hiệu quả quản trị đã trở thành một bài toán cấp bách đối với các nhà quản lý. Trong quản lý đào tạo, các trường đại học cần số hóa (chuyển đổi số) thông tin quản lý, tạo ra những hệ thống cơ sở dữ liệu lớn để tổ chức quản lý đào tạo, hỗ trợ ra quyết định quản lý một cách nhanh chóng, chính xác. Câu hỏi đặt ra là làm sao để sử dụng, phân tích, khai thác nguồn dữ liệu này một cách hiệu quả để phục vụ cho công tác quản lý giáo dục và nâng cao hiệu quả giáo dục.
Để giải quyết được câu hỏi này, một lĩnh vực mới xuất hiện, đó là khai phá dữ liệu trong giáo dục (Romero & Ventura, 2010). Lĩnh vực này sử dụng các mô hình khai phá dữ liệu, các kỹ thuật học máy để trích rút tri thức tiềm ẩn trong các dữ liệu giáo dục. Từ đó đến nay, lĩnh vực này càng ngày càng phát triển và đạt được nhiều thành tựu đáng kể.
Học máy và khai phá dữ liệu lớn là một lĩnh vực phát triển rất nhanh chóng, là lĩnh vực giao thoa giữa nhiều lĩnh vực liên quan như: cơ sở dữ liệu, thống kê, học máy, thuật toán học và các lĩnh vực liên quan khác nhằm trích rút ra những tri thức hữu ích từ những tập dữ liệu rất lớn. Người ta cũng có thể sử dụng những tên khác cho khai phá dữ liệu và khám phá tri thức như: khám phá tri thức trong cơ sở dữ liệu (Knowledge discovery in databases – KDD), trích chọn tri thức (Knowledge extraction – KE), phân tích dữ liệu hay mẫu (Data/pattern analysis – DA/PA) hay kinh doanh thông minh hoặc tri thức doanh nghiệp (Business Intelligence – BI).
Trong hai thập kỷ qua, đã có những tiến bộ đáng kể trong lĩnh vực học máy. Lĩnh vực này nổi lên như một phương pháp được lựa chọn để phát triển phần mềm thực tế cho thị giác máy tính, nhận dạng giọng nói, xử lý ngôn ngữ tự nhiên, điều khiển robot và các ứng dụng khác. Với tác động tích cực của sự gia tăng số lượng dữ liệu giáo dục thông qua số hóa, có khá nhiều lĩnh vực mà học máy có thể tác động tích cực đến giáo dục, có thể khẳng định rằng đây là xu hướng tất yếu minh chứng cho sự phát triển của giáo dục và đào tạo gắn liền với công nghệ.
Tuyển sinh đầu vào là một trong những hoạt động quan trọng của bất kì cơ sở giáo dục đại học nào. Hàng năm, mọi cơ sở giáo dục đại học ở Việt Nam đều xây dựng đề án tuyển sinh cho trường mình. Mục đích của đề án tuyển sinh là tuyển chọn đủ số lượng sinh viên theo chỉ tiêu đã được phân bổ và quan trọng hơn là tuyển đúng đối tượng sinh viên có nguyện vọng theo học ngành học phù hợp.
Đề án tuyển sinh của các trường đại học thường được giao cho bộ phận quản lý đào tạo và các đơn vị tổ chức đào tạo lên kế hoạch và triển khai thực hiện. Trong một số trường đại học còn có một trung tâm/phòng/bộ phận chuyên trách tổ chức thực hiện nhiệm vụ tuyển sinh của nhà trường. Quá trình thực tế được triển khai tại hầu hết các cơ sở giáo dục đều dưạ trên kinh nghiệm của cán bộ phụ trách việc tuyển sinh và nếu có thì đựa trên các phép phân tích định tính số liệu tuyển sinh các năm trước. Cách làm này dẫn đến hiệu quả/kết quả tuyển sinh thường không đạt được mong muốn.
Tiếp cận các vấn đề tuyển sinh của trường đại học dưới góc độ khai phá dữ liệu, ứng dụng kỹ thuật học máy, thì bài toán lập phương án tuyển sinh và các vấn đề liên quan là một trong những bài toán có độ phức tạp cao. Ở Việt Nam và kể cả trên thế giới, bài toán này còn ít phổ biến trong các nghiên cứu về giáo dục.
Trong bài báo này, chúng tôi ứng dụng các kỹ thuật học máy để giải quyết một số vấn đề trong bài toán tuyển sinh của trường đại học, trong đó dữ liệu được lấy mẫu từ Trường Đại học Thủ đô Hà Nội như một trường hợp nghiên cứu. Trong khuôn khổ của bài báo này, dựa trên nền tảng công nghệ học máy, câu hỏi nghiên cứu chúng tôi đặt ra là:
- Bộ dữ liệu cần có những thông số nào để có thể sử dụng kỹ thuật học máy để phân tích và dự báo kết quả học tập của sinh viên (cụ thể là dự báo loại tốt nghiệp dựa trên nhưng dữ liệu đầu vào được cung cấp)?
- Cần sử dụng mô hình học máy nào để giải quyết bài toán dự báo kết quả học tập đạt hiệu quả tốt?
- Các yếu tố ảnh hưởng tới kết quả đầu ra của sinh viên là gì, thuộc tính nào là quan trọng nhất trong dữ liệu đầu vào ảnh hưởng tới kết quả đầu ra của sinh viên (cụ thể là điểm thi môn nào trong tổ hợp tuyển sinh sẽ là nhân tố quan trọng nhất để đạt được kết quả đầu ra kỳ vọng) và kỹ thuật học máy nào nên sử dụng để giải quyết bài toán này?
- Có những khuyến nghị gì về chính sách đào tạo, chính sách tuyển sinh, phương pháp giải quyết hiệu quả và định lượng các vấn đề trong tuyển sinh đại học cho các trường đại học nói chung, Trường Đại học Thủ đô Hà Nội nói riêng?
Để trả lời các câu hỏi trên, chúng tôi tiến hành nghiên cứu trên bộ dữ liệu gồm 2763 mẫu với 89 trường dữ liệu của trường Đại học Thủ đô Hà Nội. Các kỹ thuật học máy được sử dụng bao gồm kỹ thuật Logistic Regression (để dự báo kết quả tốt nghiệp của sinh viên) và một kỹ thuật cải tiến của kỹ thuật Linear discriminant analysis (để dự báo nhân tố quan trọng ảnh hưởng tới kết quả học tập của sinh viên)-kỹ thuật Discriminative Feature Selection. Câu trả lời cho các vấn đề nêu trên sẽ được trình bày chi tiết trong mục 4 (results) và mục 5 (Discussion). Trước đó, trong mục 2, chúng tôi phân tích tổng quan các nghiên cứu về khoa học dữ liệu trong giáo dục, trong đó đặc biệt nhấn mạnh đến ứng dụng của các kỹ thuật học máy trong việc xử lý các dữ liệu trong nghiên cứu giáo dục. Quá trình xây dựng bộ dữ liệu tuyển sinh và các trường thuộc tính tạo nên tập dữ liệu huấn luyện và kiểm thử dùng cho máy học sẽ được trình bày trong mục 3 cùng với mô tả chi tiết phương pháp lựa chọn kỹ thuật học máy và cách thức xử lý dự liệu đầu vào (dữ liệu tập trung phân tích cho ngành Giáo dục Tiểu học của Trường Đại học Thủ đô Hà Nội, dữ liệu trong 5 năm từ 2016 đến 2020). Cuối cùng, một số hướng nghiên cứu nhằm nâng cao hiệu quả dự báo được trình bày trong mục 6 (conclusion).
Tổng quan nghiên cứu
Khai phá dữ liệu (Data mining) là quá trình khám phá ra các thông tin có giá trị hoặc đưa ra các dự báo từ dữ liệu. Tác giả (Hồ, 2002) đã khái quát hóa một số khái niệm liên quan đến lĩnh vực Phát hiện tri thức và Khai phá dữ liệu được đề cập trong bài giảng Introduction to Knowledge Discovery and Data Mining nhằm hệ thống hóa những kiến thức nền tảng về lĩnh vực này.
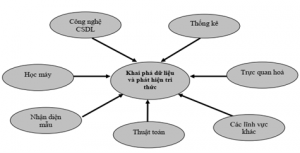
Hình 1: Mối quan hệ của khai phá dữ liệu và phát hiện tri thức với các lĩnh vực khác có liên quan
Đối với lĩnh vực Học máy, một ưu điểm đối với công nghệ này đó là các máy tính không cần phải được lập trình một cách rõ ràng và cụ thể, các máy tính có đầy đủ khả năng thay đổi và cải thiện các yếu tố về thuật toán, hay nói cách khác máy tính tiệm cận với công nghệ trí tuệ nhân tạo (AI). Để thể hiện mức độ phức tạp và mức độ thông minh của học máy trong giải quyết các bài toán thực tế, (Webber. & Zheng, n.d.) đã đưa ra sơ đồ sau:

Các kỹ thuật học máy để khai phá dữ liệu được ứng dụng trong rất nhiều lĩnh vực trong đó có khoa học giáo dục. Đặc biệt là trong bối cảnh giáo dục có nhiều thay đổi dưới sự tác động của cuộc cách mạng 4.0, công nghệ đã trở thành một phần tư liệu sản xuất của quá trình giáo dục. Mặt khác, nhu cầu học tập cá nhân cũng được chú trọng. Do đó, các nghiên cứu giáo dục học đang được chuyển hướng đến nghiên cứu sâu hành vi người học để thiết lập các chương trình học cá nhân; đồng thời khai phá dữ liệu lớn những người học để sớm chẩn đoán và định hướng lại quá trình học tập của người học nói riêng, quản lí/ điều hành quá trình giáo dục nói chung. Đó cũng là những nội dung mà học máy có thể được ứng dụng trong nghiên cứu khoa học giáo dục.
Một nghiên cứu được thực hiện bởi (Kotsiantis, 2012), đã mô tả lĩnh vực mới nổi của máy học về giáo dục. Trong nghiên cứu này, các dữ liệu đặc trưng của sinh viên và dữ liệu điểm được khai thác dưới dạng tập dữ liệu cho phương pháp học máy hồi quy được sử dụng để dự báo khả năng học tập trong tương lai của sinh viên. Bài toán dự báo kết quả học tập của học sinh được đề xuất nghiên cứu bởi (Anozie & Junker, 2006). (Đambić et al., 2016) đã đề xuất các giải pháp để giảm số học sinh lưu ban, bị đuổi học vì kết quả học tập kém, cải thiện tỷ lệ qua môn cho sinh viên bằng cách phân tích, sử dụng kỹ thuật học máy để xác định những học sinh “có nguy cơ”, từ đó nhà trường có thể tạo những trợ giúp cần thiết để giúp học sinh cải thiện kết quả học tập.
Gần đây, (Wu et al., 2020) đã nghiên cứu sử dụng máy học cho việc phân loại văn bản để chấm điểm cuối khóa của sinh viên trong một số khóa học, thể hiện tiềm năng sử dụng các thông điệp được phân loại bằng máy học để xác định học sinh có nguy cơ trượt khóa học. Các kết quả ứng dụng học máy trong nghiên cứu lĩnh vực giáo dục cho thấy tiềm năng lớn trong việc giải quyết bài toán dự báo kết quả sinh viên cũng như bài toán tuyển sinh đã đặt ra.
Đã có nhiều nghiên cứu liên quan đến phương pháp khai phá dữ liệu như: Cây quyết định, KNN, Bayes, Luật kết hợp… để giải quyết vấn đề dự báo năng lực sinh viên và mang lại nhiều kết quả khả quan (Xu et al., 2021), (Damuluri et al., 2020), (Thai-Nghe et al., 2011), (Nghe & Định, 2015). Tận dụng các tính năng ưu việt của hệ thống Mymedialite, (Nghe, 2013) đã xây dựng phương pháp dự báo năng lực sinh viên. Một nghiên cứu khác sử dụng hai thuật toán khai phá dữ liệu Naïve Bayes và Logistic Regression cũng cho một số kết quả khả quan trong việc dự báo kết quả học tập và dự báo tình trạng bị buộc ngừng học (Uyên & Tâm, 2019). Với thuật toán này có thể chỉ ra chính xác sinh viên cần phải nỗ lực học tập các học phần nào để có thể giảm thiểu nguy cơ buộc ngừng học.
Một số công trình hiện có đã tập trung vào các thuật toán học có giám sát như Thuật toán Naive Bayesian, khai thác quy tắc kết hợp, thuật toán dựa trên mạng nơron nhân tạo (ANN), Hồi quy logistic, CART, C4.5, J48, (BayesNet), SimpleLogistic, JRip, RandomForest, Phân tích hồi quy logistic, ICRM2 cho phân loại học sinh bỏ học (Kumar et al., 2017). Tuy nhiên, theo kỹ thuật phân loại, Mạng nơron và Cây quyết định là hai phương pháp được các nhà nghiên cứu sử dụng nhiều để dự đoan kết quả học tập của học sinh (Shahiri et al., 2015). Ưu điểm của mạng nơron là nó có khả năng phát hiện tất cả các tương tác có thể có giữa các biến dự báo và cũng có thể thực hiện phát hiện hoàn chỉnh ngay cả trong quan hệ phi tuyến phức tạp giữa các biến phụ thuộc và độc lập (Arsad et al., 2013), trong khi cây quyết định đã được sử dụng vì tính đơn giản và dễ hiểu của nó để khám phá cấu trúc dữ liệu nhỏ hoặc lớn và dự báo giá trị (Natek & Zwilling, 2014).
Trong (Elbadrawy et al., 2016), hai lớp phương pháp xây dựng mô hình dự báo đã được trình bày. Mục đích của nghiên cứu được thực hiện là tạo điều kiện thuận lợi cho việc lập kế hoạch cấp bằng và xác định ai có nguy cơ trượt hoặc rớt lớp. Lớp đầu tiên xây dựng mô hình bằng cách sử dụng phương pháp hồi quy tuyến tính và lớp thứ hai sử dụng phương pháp phân tích ma trận. Các phương pháp dựa trên hồi quy mô tả hồi quy theo khóa học cụ thể và hồi quy đa tuyến tính được cá nhân hóa trong khi các phương pháp dựa trên phân tích ma trận kết hợp với cách tiếp cận phân rã ma trận chuẩn. Cách tiếp cận đã đề cập được áp dụng trên tập dữ liệu được tạo từ dữ liệu bảng điểm của Đại học George Mason (GMU), dữ liệu bảng điểm của Đại học Minnesota (UMN), dữ liệu UMN LMS và dữ liệu MOOC của Đại học Stanford.
Từ tổng quan nêu trên, chúng ta có thể thấy các vấn đề giáo dục được giải quyết thông qua khai phá dữ liệu là khá phong phú. Bài toán dự báo kết quả học tập của học sinh đã được quan tâm nghiên cứu bởi nhiều tác giả và các kỹ thuật khai phá dữ liệu được sử dụng rất đa dạng. Tuy nhiên, dữ liệu sử dụng trong các nghiên cứu này chủ yếu dựa vào bảng điểm kết quả học tập quá trình của sinh viên. Vấn đề phân tích dữ liệu tuyển sinh đầu vào của sinh viên đại học, và phân tích ảnh hưởng của dữ hiệu tuyển sinh trong bài toán dự báo kết quả tốt nghiệp của sinh viên là một vấn đề mới, chưa được đặt ra nghiên cứu. Hơn nữa, việc sử dụng kỹ thuật Linear discriminant analysis để dự báo nhân tố quan trọng trong dữ liệu tuyển sinh ảnh hưởng tới kết quả học tập của sinh viên là một nét điển hình trong bài báo này, đặc biệt là trong ngữ cảnh xử lý dữ liệu tại Việt Nam. Đây là vấn đề hay và mới được đặt ra.
Phương pháp
Phần lớn các bài toán học máy có thể được thể hiện trong mô hình dưới đây:
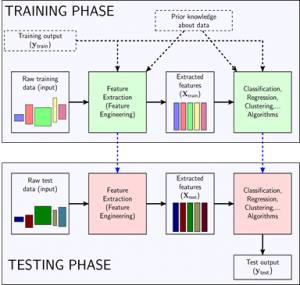
Hình 3. Mô hình chung cho các bài toán học máy (Tiệp, 2018)
Trong mô hình này, có hai phases lớn là Training phase và Testing phase. Với các bài toán thuộc Supervised learning, ta có các cặp dữ liệu (input, output), với các bài toán Unsupervised learing, ta chỉ có input. Hiểu đơn giản training là tập dữ liệu đưa vào huấn luyện sau dùng tập testing để kiểm tra lại kết quả thông qua các bài toán hồi quy, bài toán phân lớp, …
Mỗi bài toán, mỗi mô hình dự báo đều có những ưu và nhược điểm riêng. Từ những đặc điểm của bộ dữ liệu huấn luyện xây dựng được, nhà nghiên cứu phải xây dựng các mô hình, thuật toán phù hợp để giải quyết các câu hỏi đặt ra trong từng trường hợp cụ thể.
Dữ liệu được sử dụng cho bài báo này là dữ liệu tuyển sinh và dữ liệu đào tạo của Trường Đại học Thủ đô Hà Nội. Trường Đại học Thủ đô Hà Nội, mã trường HNM, là trường đại học công lập trực thuộc Ủy ban Nhân dân thành phố Hà Nội. Trường Đại học Thủ đô Hà Nội là cơ sở giáo dục đào tạo đại học trong hệ thống giáo dục quốc dân, tổ chức đào tạo nguồn nhân lực đa ngành, đa lĩnh vực trình độ cao đẳng, đại học và trên đại học; tổ chức các hoạt động giáo dục nghề nghiệp theo nhu cầu xã hội và theo quy định của pháp luật. Ngành Giáo dục Tiểu học là một trong những ngành truyền thống của Nhà trường, bắt đầu tuyển sinh từ năm 1959, ngành Giáo dục Tiểu học của Trường Đại học Thủ đô Hà Nội đã cung cấp lượng giáo viên tiểu học lớn cho các trường tiểu học trên địa bàn Thành phố Hà Nội và các địa bàn lân cận. Trong bài báo này, chúng tôi xét vấn đề tuyển sinh trình độ đại học, hệ chính quy, ngành Giáo dục Tiểu học của Trường Đại học Thủ đô Hà Nội.
Hàng năm, bộ phận quản lý đào tạo của nhà trường đều có dữ liệu thống kê kết quả các môn học của sinh viên các ngành học trong trường. Phòng Quản lý đào tạo và Công tác học sinh sinh viên được cấp Phiếu điểm tốt nghiệp cho sinh viên, đánh giá và trách nhiệm giải trình, thông tin về nhà giáo dục, và tài chính của nhà trường với Ủy ban Nhân dân thành phố Hà Nội và Bộ Giáo dục và Đào tạo. Các dữ liệu thô được cung cấp bởi các Khoa đào tạo và phòng Quản lý đào tạo và Công tác học sinh sinh viên. Tất cả dữ liệu, bao gồm điểm tuyển sinh đầu vào, điểm các học phần năm 1, năm 2, năm 3, năm 4, điểm thực tập và điểm tốt nghiệp, tình hình tài chính có thể được trích xuất từ phần mềm quản lý đào tạo để phân tích dữ liệu. Bộ dữ liệu bao gồm 2763 mẫu quan sát của sinh viên ngành Giáo dục tiểu học từ khóa D2016 đến khóa D2020 và 33 biến thuộc tính. Mỗi mẫu quan sát được thể hiện bằng 1 hàng.
Bài toán dự báo xếp loại học tập và bài toán xác định thuộc tính quan trọng được thực hiện theo các bước sau:
Bước 1: Thu thập dữ liệu thông tin kết quả học tập của sinh viên
Bước 2: Tiền xử lý dữ liệu
Bước 3: Tách dữ liệu thu thập được thành hai tập, một tập là huấn luyện, tập còn lại là tập kiểm thử
Bước 4: Huấn luyện
Bước 4.1 Huấn luyện mô hình dự báo theo phương pháp Hồi quy logistic với hàm softmax
Bước 4.2 Huấn luyện mô hình xác định thuộc tính quan trọng theo phương pháp trong (Masaeli et al., 2010).
Bước 5: Sử dụng mô hình dự báo để dự báo kết quả học tập của sinh viên và xác định thuộc tính quan trọng
Bước 6: Đánh giá kết quả, độ chính xác của mô hình dự báo
Kết quả
Bộ dữ liệu
Các dữ liệu đầu vào bao gồm 4 trường thuộc tính dữ liệu tuyển sinh (điểm thi trung học phổ thông quốc gia môn Toán, môn Văn, môn Tiếng Anh và tổng điểm thi) và 85 điểm môn học thành phần (bao gồm cả những môn học tự chọn khác nhau cho mỗi sinh viên).
Dữ liệu đã được làm sạch, loại bỏ các biến dữ liệu không cần thiết và các biến không được đánh giá trong nghiên cứu này. Chúng tôi đã loại bỏ một số dữ liệu về các môn học thể chất hay năng khiếu, và biến số liên quan đến tài chính của sinh viên. Đồng thời các thuộc tính có quá ít dữ liệu, hoặc có nhiều dữ liệu trống cũng được loại bỏ. Các môn tự chọn phần lớn rơi vào mảng dữ liệu trống này. Chúng tôi cũng tập trung vào dữ liệu điểm kiểm tra cụ thể và loại bỏ phần dữ liệu điểm chữ của dữ liệu điểm kiểm tra. Chúng tôi đã chọn các biến cụ thể cho từng sinh viên để kiểm tra mối tương quan của chúng với biến quan tâm. Do đó, từ 2763 mẫu với 89 biến thuộc tính, tập dữ liệu đã được làm sạch để chỉ bao gồm dữ liệu của 933 mẫu quan sát và các biến được giới hạn ở 39 biến.
Dữ liệu được chia thành các tập con huấn luyện và thử nghiệm. Tập huấn luyện bao gồm 90% tập dữ liệu gốc và tập thử nghiệm chứa 10%.
Hình 4: Huấn luyện mô hình
Dữ liệu được hiển thị cho hai trường hợp dự báo:
Trường hợp 1: căn cứ vào Điểm tuyển sinh THPTQG và điểm thi học phần các môn năm thứ nhất đại học.
Trường hợp 2: căn cứ vào Điểm tuyển sinh THPTQG và điểm thi học phần các môn năm thứ nhất và năm thứ hai đại học.
Cả hai mô hình đều được sử dụng để đưa ra dự báo về kết quả học tập của sinh viên và các mô hình này đã được phân tích về độ chính xác.
Kỹ thuật học máy sử dụng trong dự báo
Bài toán mà chúng tôi giải quyết trong bài báo này có hai bài toán con chính đó là (1) dự báo xếp loại học tập và (2) xác định thuộc tính quan trọng.
Tập dữ liệu kết quả học tập của sinh viên thu được từ trường Đại học Thủ đô ở trên là không tách được tuyến tính nên một số phương pháp học máy như hồi quy tuyến tính, PLA,… không áp dụng được. Bài toán phân loại kết quả học tập ở trên là bài toán đa lớp dẫn đến hồi quy logistics với hàm sigmoid sẽ không hiệu quả. Do đó chúng tôi đề xuất áp dụng hồi quy logistics với hàm softmax cho bài toán con thứ nhất. Với thuật toán này, đầu ra có thể được thể hiện dưới dạng xác suất (probability).
Bài toán con thứ hai đó là xác định thuộc tính quan trọng (cụ thể là xác định môn nào là quan trọng nhất trong số các môn thi tuyển sinh của tập dữ liệu đầu vào). Việc xác định thuộc tính quan trọng là một bài toán tối ưu NP-Hard trên không gian rời rạc. Do đó, việc nghiên cứu tìm thuật toán lựa chọn đặc trưng có độ phức tạp thấp hơn là một vấn đề quan trọng khi giải bài toán con thứ hai này. Một cách thích hợp để giải bài toán con thứ hai với độ phức tạp tính toán chấp nhận được đó là quy bài toán tối ưu trên không gian rời rạc về bài toán tối ưu trên không gian liên tục như trong (Tao 2016). Kỹ thuật được sử dụng là kỹ thuật Discriminative Feature Selection. The feature selection method (combining the popular transformation-based dimensionality reduction method linear discriminant analysis and sparsity regularization in Tao 2016) will be used to deal with this problem.
Dự báo kết quả học tập của sinh viên
Hồi quy logistic là kỹ thuật phân loại đầu tiên được sử dụng để kiểm tra tập dữ liệu này. Điểm Toán, Văn, Anh được chọn làm các biến số quan tâm cho tất cả các kỹ thuật phân loại. Điểm của năm 1, năm 2 đều có mối tương quan cao, với bất kỳ biến số nào trong số này đều có thể được sử dụng để đánh giá. Kết quả dự báo được thể hiện trong Hình 5.
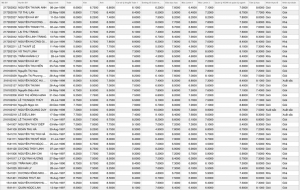
Hình 5: Dự báo kết quả học tập của sinh viên
Phân tích hồi quy logistic được sử dụng để kiểm tra mã tốt nghiệp trên mỗi sinh viên, dựa trên 39 trường dữ liệu đầu vào, số điểm thi trung học phổ thông quốc gia, số điểm thi học phần của 35 môn học trong 2 năm đầu. Bài toán được tiếp cận với 2 mức độ của các dữ liệu đầu vào: Mức độ 1 dựa trên 22 thuộc tính gồm điểm xét tuyển đại học và 18 môn học của năm thứ nhất đại học, Mức độ 2 là phân tích dựa trên tổng thể 39 điểm số của 35 môn học năm thứ nhất và thứ hai đại học, cùng với điểm thi tốt nghiệp trung học phổ thông quốc gia (4 thuộc tính).
Mức độ 1, sau khi huấn luyện và kiểm thử, kết quả trả về trong Hình 5.
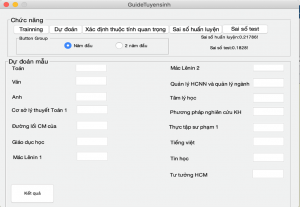
Hình 6: Đánh giá mô hình năm đầu
Kết quả nhận được có sai số huấn luyện là 21% và sai số kiểm thử là 18%.
Hình 7 mô tả kết quả dự báo khi sử dụng mô hình ở Mức độ 2, dựa trên tổng thể 39 điểm số của 35 môn học năm thứ nhất và thứ hai đại học, cùng với điểm thi tốt nghiệp trung học phổ thông quốc gia. Kết quả nhận được có sai số huấn luyện là 18% và sai số kiểm thử là 15%. Sai số ở mức chấp nhận được và phù hợp với dữ liệu thống kê.
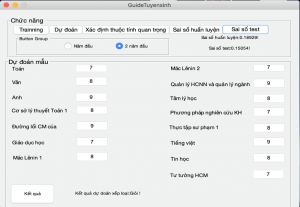
Hình 7: Đánh giá mô hình 2 năm đầu
Một trong những đặc điểm mới của nghiên cứu này là chúng tôi có xây dựng được bộ dữ liệu mới và cho chạy chương trình thử nghiệm dự báo. Kết quả kiểm thử mô hình dự báo được thể hiện trong Hình 8. Khi ta có dữ liệu thi Trung học phổ thông quốc gia và điểm số của 1 năm đầu hoặc 2 năm đầu của sinh viên, dựa vào chương trình xây dựng, ta có thể dự báo được loại tốt nghiệp kỳ vọng của sinh viên đó. Với 180 mẫu dữ liệu mới, chương trình cho ta kết quả dự báo loại tốt nghiệp của 180 sinh viên đó. Kết quả được thể hiện trong Hình 9.
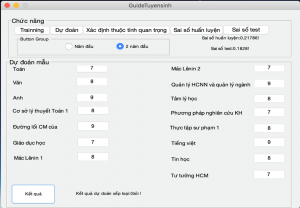
Hình 8: Test dữ liệu mới
Dự báo yếu tố ảnh hưởng chính tới kết quả đầu ra
Việc xác định thuộc tính quan trọng nhất được xây dựng dựa trên kỹ thuật Discriminative Feature Selection (see Tao 2016) với nhiều trường dữ liệu và thư viện con được xây dựng.
Thuộc tính quan trọng nhất ảnh hưởng tới kết quả đầu ra của sinh viên có tương quan nhiều kết quả đầu ra của sinh viên đó, nhưng không tương quan với quy mô các thuộc tính hay quy mô tập dữ liệu. Các dữ liệu có tổng điểm tuyển sinh cao hơn sẽ có tương quan với loại tốt nghiệp tốt hơn. Các yếu tố môn học nghệ thuật, thể chất, chính trị học, các môn chung được cho thấy có mối tương quan nhẹ với điểm tổng điểm tốt nghiệp của sinh viên. Các số liệu huấn luyện và kiểm thử hiển thị các mối quan hệ giữa điểm Văn và các biến còn lại, với tổng điểm tốt nghiệp của sinh viên và loại tốt nghiệp
Hình 9 mô tả kết quả huấn luyện cho tập huấn luyện gồm các mẫu số liệu của sinh viên ngành Giáo dục tiểu học, trường Đại học Thủ đô Hà Nội. Theo kết quả huấn luyện này, trong các môn thuộc tổ hợp tuyển sinh đầu vào cho ngành giáo dục Tiểu học của Trường Đại học Thủ đô Hà Nội, môn Văn sẽ là thuộc tính quan trọng nhất ảnh hưởng tới kết quả đầu ra của sinh viên. Dữ liệu đầu vào được
xét bao gồm thông tin tuyển sinh và kết quả học tập của hai năm đầu đại học của sinh viên.
Hình 9. Thuộc tính quan trọng nhất.
Thảo luận
Có nhiều bộ phân loại khác nhau được sử dụng để đánh giá độ chính xác của một mô hình cho bộ dữ liệu về tuyển sinh và quá trình học tập của sinh viên. Tiến hành thu thập, tổng hợp, phân tích dữ liệu của các bên liên quan đến giáo dục là một quá trình mất nhiều thời gian, tốn kém và không phải lúc nào cũng có mức độ chính xác cao, nhất là trong thực trạng việc chuyển đổi số và lữu trữ dữ liệu dạng số trong lĩnh vực giáo dục ở Việt Nam còn chưa được tiến hành bài bản và triệt để, trong đó có trường Đại học Thủ đô Hà Nội. Việc quản lý thông tin tuyển sinh, trong đó có điểm thi trung học phổ thông quốc gia, do Bộ giáo dục và đào tạo quản lý. Trong khi đó các trường Đại học chỉ quản lý dữ liệu điểm thi của các môn học trong quá trình đào tạo và điểm tốt nghiệp. Thực tế hiện nay, mặc dù các trường đại học đều đã quan tâm đến việc xây dựng tập dữ liệu sinh viên nhưng dữ liệu được xây dựng, quản lý bởi nhiều bộ phận khác nhau (phòng đào tạo, phòng công tác học sinh sinh viên, các khoa đào tạo…). Các dữ liệu vì thế khó đồng bộ, việc kết nối để khai thác và sử dụng dữ liệu của các bên liên quan cũng gặp nhiều khó khăn.
Mặt khác, các dữ liệu khác của sinh viên như: văn hóa, truyền thống gia đình, kinh tế, nguyện vọng cá nhân, định hướng nghề nghiệp, kết quả học tập phổ thông, kế hoạch học tập, chương trình đào tạo, đội ngũ giảng viên, cơ sở vật chất của cơ sở giáo dục, việc tham gia các tổ chức xã hội, đoàn thể, yếu tố nhân chủng học, yếu tố văn hóa, kinh tế, tâm lý học,… cần được nghiên cứu xây dựng cần đảm bảo tập dữ liệu gồm nhiều trường thông tin, nhiều tham số đại diện, ảnh hưởng qua lại lẫn nhau trực tiếp ảnh hưởng tới quá trình đào tạo của SV và kết quả học tập của sinh viên đó. Các yếu tố này cần được phân tích, xử lý, đưa ra cách thức cải thiện để làm cho dữ liệu giáo dục có ý nghĩa hơn đối với sinh viên, giảng viên và các bên liên quan khác.
Chính vì vậy, Bộ giáo dục và đào tạo, Sở giáo dục và đào tạo ở các địa phương và các cơ sở giáo dục đại học cần quan tâm một cách nghiêm túc đến việc xây dựng bộ dữ liệu lớn, đồng bộ, liên thông giữa các đơn vị quản lý và các cơ sở giáo dục nhằm khai thác một cách có hiệu quả các dữ liệu trên phục vụ công tác quản lý và nâng cao chất lượng giáo dục.
Kết quả dự báo có thể tốt hơn nếu nó cung cấp cho các nhà giáo dục thông tin có thể được sử dụng để giúp cải thiện kết quả học tập của sinh viên. Việc phân tích dữ liệu có thể gặp vấn đề nếu thiếu dữ liệu, trường dữ liệu trống hoặc nếu có lỗi trong mô hình.
Việc xác định kỹ thuật học máy phù hợp để phân loại chính xác, dự báo chính xác (với sai số chấp nhận được) kết quả học tập của sinh viên cũng là một trong những yếu tố cốt lõi để đi đến thành công của nghiên cứu này.
Kết quả dự báo cho loại tốt nghiệp của sinh viên, trong cả hai trường hợp đều cho thấy mối quan hệ tăng dần độ chính xác với một sự giảm dần độ lệch chuẩn trong kết quả dự báo (sai số từ 21% đến 15% trên tập huấn luyện và kiểm thử). Điều này có thể giải thích tại sao các trường đại học nên chuyển hướng tích cực sang việc dạy học hai giai đoạn. Dựa trên quy mô đào tạo đại cương và điểm số tuyển sinh, điểm học năm thứ nhất và thứ hai đại học, chúng ta có thể dự báo được những sở trường của sinh viên phù hợp với ngành nghề đào tạo nào của trường Đại học Thủ đô Hà Nội nói riêng, các trường đại học nói chung (khi có dữ liệu phù hợp).
Đồng thời kết quả này cũng phản ánh trung thực việc tập dữ liệu càng có nhiều thuộc tính (độ phức tạp của tập dữ liệu càng cao) thì kết quả dự báo càng chính xác.
Việc xác định kết quả dự báo cho nhân tố ảnh hưởng chính đến kết quả tốt nghiệp của sinh viên trong các môn của tổ hợp tuyển sinh sẽ hỗ trợ những nhà quản lý ra quyết định trong việc chọn các tổ hợp tuyển sinh phù hợp với định hướng chuẩn đầu ra của ngành. Đồng thời xác định hệ số cho mỗi môn trong tổ hợp tuyển sinh phù hợp sao cho lựa chọn được những sinh viên có lực học phù hợp nhất với yêu cầu của ngành nghề đào tạo.
Mặt khác việc tính được các yếu tố ảnh hưởng chính tới kết quả đầu ra của sinh viên cũng cho phép cơ sở giáo dục đào tạo đại học thúc đẩy chất lượng hoạt động của đội ngũ cố vấn học tập, định hướng việc lựa chọn chuyên ngành, môn học phù hợp với từng sinh viên.
Tổng kết
Mô hình phân loại hồi quy logistic có thể được sử dụng để đưa ra dự báo về các thước đo hiệu suất khác, sử dụng cùng một tập dữ liệu. Các nhà giáo dục có thể sử dụng mô hình để chọn các biến mà họ muốn đánh giá mối tương quan giữa các biến được sử dụng để dự báo kết quả học tập của sinh viên trong các bài đánh giá. Mô hình dự báo này sau đó có thể được sử dụng để thực hiện can thiệp sớm cho sinh viên, điều này có thể giúp cải thiện sự thành công trong tương lai của sinh viên. Phản hồi kịp thời là điều quan trọng đối với các nhà giáo dục để có thể đưa ra các chiến lược can thiệp sớm. Mô hình này có thể được thực hiện nhanh chóng và dễ dàng sau khi tập dữ liệu được xây dựng
Mô hình hồi quy logistic có thể được cải thiện để đưa ra dự báo tốt hơn về kết quả học tập của sinh viên. Sẽ rất thú vị nếu so sánh hiệu suất của các mô hình phân loại trên các tập dữ liệu khác, hoặc thậm chí cải thiện mô hình để tăng độ chính xác dự báo của mô hình hiện tại.
Từ kết quả phân tích bước đầu chúng tôi thấy bài toán tuyển sinh có thể được giải quyết một cách triệt để, định lượng. Nếu nhập đầy đủ thông tin dữ liệu đầu vào như điểm học các môn học 3 năm cấp 3, điều kiện kinh tế gia đình, sở thích và hứng thú nghề nghiệp, kĩ năng tự học, tự nghiên cứu tài liệu… việc dự báo thành tích học tập của sinh viên là hoàn toàn có thể. Từ đó bài toán tuyển sinh không dừng ở phạm vi xây dựng đề án tuyển sinh mà còn mở rộng ra lĩnh vực tư vấn tuyển sinh.
Nghiên cứu trong tương lai cũng có thể bao gồm đánh giá các đặc điểm hành vi của sinh viên, các yếu tố nhân học, yếu tố cá nhân và yếu tố lịch sử của quá trình học tập của sinh viên, cũng như thái độ học tập và các yếu tố kinh tế xã hội khác khi chúng liên quan đến kết quả học tập của sinh viên dựa trên các cách thức đánh giá. Có thể tiến hành phân tích bổ sung bằng cách sử dụng các bộ phân loại khác nhau trên cùng một tập dữ liệu, bao gồm nhận thức đa lớp và mạng nơ-ron nhân tạo.
Tác giả:
PGS. TS Chu Cẩm Thơ
Viện Khoa học Giáo dục Việt Nam.
101 Trần Hưng Đạo, Hoàn Kiếm, Hà Nội, Việt Nam
Email: thocc@vnies.edu.vn
Nguồn:
Kỷ yếu Hội thảo Khoa học quốc tế “Đổi mới sáng tạo trong dạy học và đào tạo/bồi dưỡng giáo viên lần thứ hai – ILITE 2” năm 2021 với chủ đề “Đổi mới sáng tạo vì sự phát triển bền vững của giáo dục trong bối cảnh biến động”(Innovation for sustainable education in the changing context) – Do trường Đại học Sư phạm Hà Nội tổ chức.